
Postgres Enterprise Manager (PEM) consists of components that provide the management and monitoring for your EDB Postgres Advanced Server, EDB Postgres Extended, or PostgreSQL database.
PEM is a comprehensive database design and management system. PEM is designed to meet the needs of both novice and experienced Postgres users alike, providing a powerful graphical interface that simplifies the creation, maintenance, and use of database objects.
We are often asked about PEM’s disk usage, as it may be critical both from storage and PEM database performance point of view. The amount of data collected by PEM heavily depends on the database server(s) workload.
In this blog post, I’ll give details about sizing a PEM server.
Configuration and test environment
The test environment consists of a PEM server, and a PostgreSQL server that PEM will monitor. The PostgreSQL server runs HammerDB in a loop, generating load based on the TPC-C benchmark for PEM to monitor.
TPC-C was chosen because it's design to emulate the workload that might be seen in the application of a wholesale supplier of goods; a generic, understandable OLTP workload.
PEM server installation and configuration
In this setup, I used PEM 8.1.1 running on RHEL 8 with 8 CPUs and 16 GB of memory, and Installed all packages via EnterpriseDB’s RPM repository, located at https://repos.enterprisedb.com (you’ll need a username/password to access packages, as described in the link). Please follow EDB PEM docs for configuring PEM and PEM agent.
Database server installation and configuration
On the database server, I used PostgreSQL 13.3 running on RHEL 8 from the community RPMS found at https://yum.postgresql.org .Just like the PEM server, this instance is also an 8-CPU server, with 16 GB memory.
After initialising the cluster with the “postgresql-13-setup initdb” command, I created the following user and database for HammerDB:
- su - postgres
- psql -c “CREATE USER tpcc;”
- psql -c “CREATE DATABASE tpcc OWNER tpcc;”
Also, made the following changes to postgresql.conf:
- shared_buffers = 6GB
- work_mem = 8MB
- bgwriter_delay = 50ms
- bgwriter_lru_maxpages = 10000
- bgwriter_lru_multiplier = 2.0
- checkpoint_timeout = 30min
- wal_compression = on
- max_wal_size = 4GB
- min_wal_size = 1GB
Make sure that you restart PostgreSQL after you make these changes.
If you want to learn more about tuning, please refer to the PostgreSQL performance tuning and optimization article written by my colleague Vik Fearing.
HammerDB installation and configuration
Here are the steps to download, install and configure HammerDB:
- Download and extract HammerDB
- cd /usr/local/src
- wget https://github.com/TPC-Council/HammerDB/releases/download/v4.1/HammerDB-4.1-Linux.tar.gz
- tar zxf HammerDB-4.1-Linux.tar.gz
After these steps, I created a HammerDB config file, so that an automated script can run:
cat > /usr/local/bin/pg_hammerdb.tcl <
puts "SETTING CONFIGURATION"
dbset db pg
diset tpcc pg_driver timed
diset tpcc pg_rampup 0
diset tpcc pg_duration 1
vuset logtotemp 1
buildschema
waittocomplete
loadscript
puts "SEQUENCE STARTED"
foreach z { 1 2 4 8 16 32 64 128 } {
puts "$z VU TEST"
vuset vu $z
vucreate
vurun
runtimer 120
vudestroy
after 5000
}
puts "TEST SEQUENCE COMPLETE"
EOF
cat > /usr/local/bin/pg_hammerdb.sh <
do
cd /usr/local/src/HammerDB-4.1/
./hammerdbcli auto /usr/local/bin/pg_hammerdb.tcl
sleep 120
done
EOF
Database size
At the end of the test, the HammerDB script above generated about 95GB of data after weeks of running. As the script recreated the data after each run, the amount of bloat is negligible (About 1% at the end of each run)
What about “retention?”
Per the docs, “A probe is a scheduled task that returns a set of performance metrics about a specific monitored server, database, operating system or agent.”. There are several predefined probes within PEM, and also custom probes can be created by users.
Predefined probes have retention periods, where data is cleaned up from the PEM database. In order to perform this test, we changed retention values of the probes (many of them were 90 or more days), so that we can have an estimate of the disk usage earlier. Below are the values that we used during the testing:
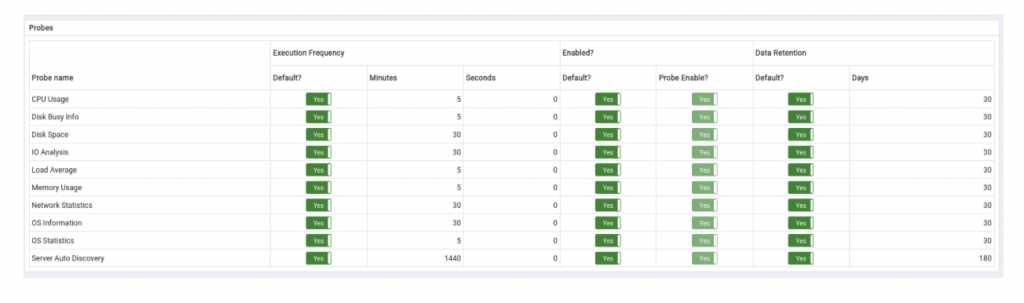
The default values may be quite high if you are monitoring multiple servers, as the amount of data will be high as the number of the database servers increase. The trick is that PEM also creates summary tables, so you actually won’t need older data after some time. Also, you can consider increasing the execution frequency on the left hand side, which will end up with less data on the PEM server.
So, what are the numbers?
PEM gives us the CPU, disk, storage (amount of data read and written to the disks), and memory statistics by default. We created 2 graphs for each of them: Historical span of 7 days and 30 days for each 4 items. All of these graphs represent the load on the PEM server.
CPU data
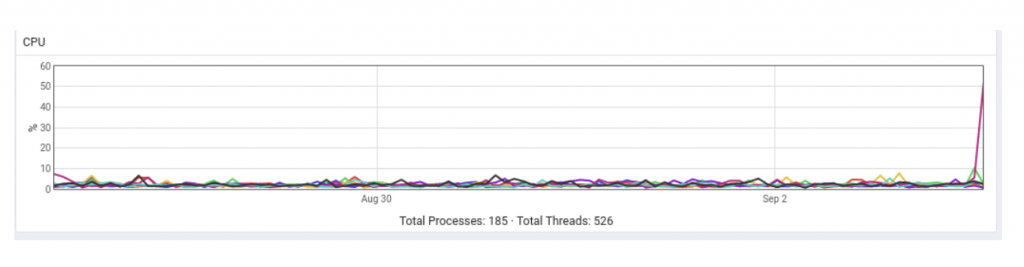
CPU: 7 days:
CPU 30 days:
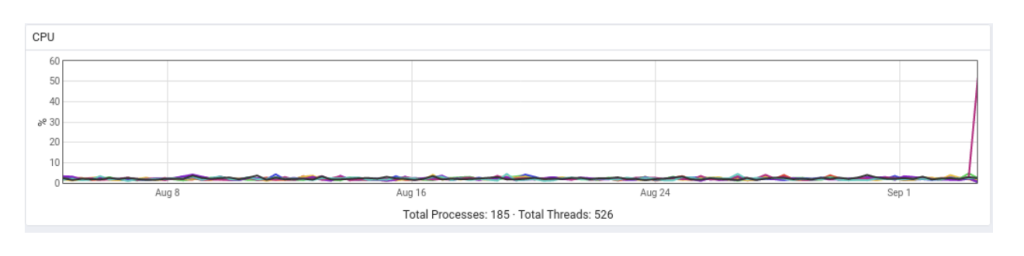
Comment on CPU usage: For 1 database server and 1 PEM server, the CPU usage is quite low. However, as the number of the database servers increase, and as more probes are added for those servers, the amount of data that will be collected in a given time will increase, and it will affect the CPU usage as well.
Disk usage data
Disk: 7 days
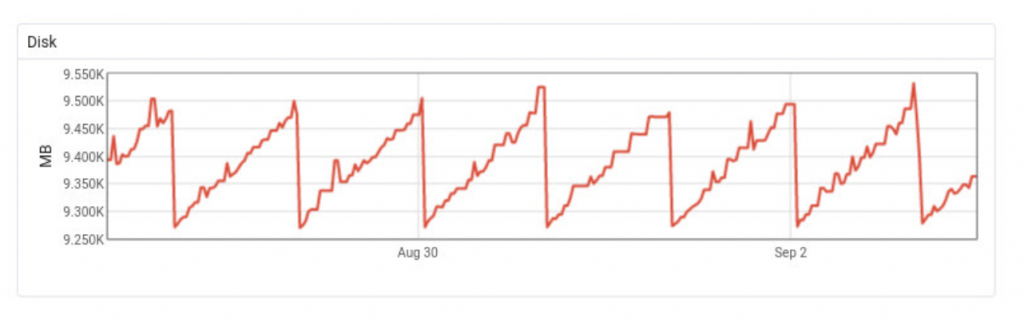
Disk: 30 days
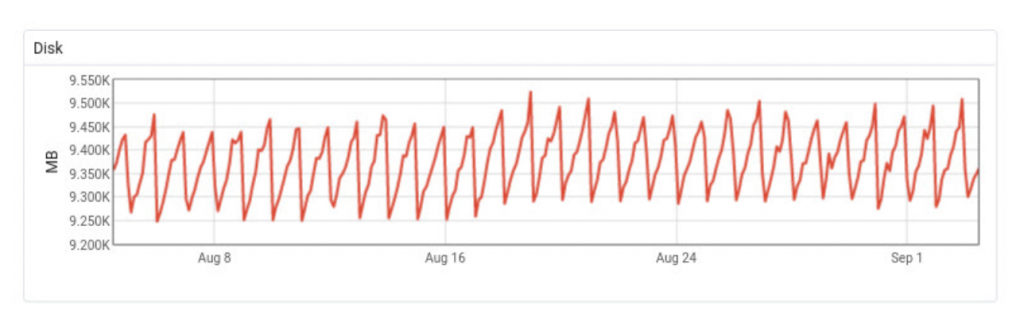
Comment on disk usage: This behaviour is heavily expected, after making the retention changes written above. With the help of autovacuum, Postgres will re-use the disk space after old data is deleted.
Storage (total I/O) data
Storage (7 days):
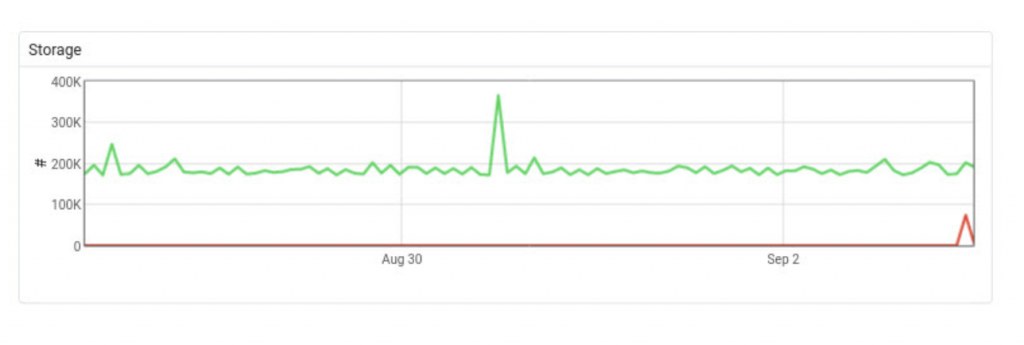
Storage: 30 days
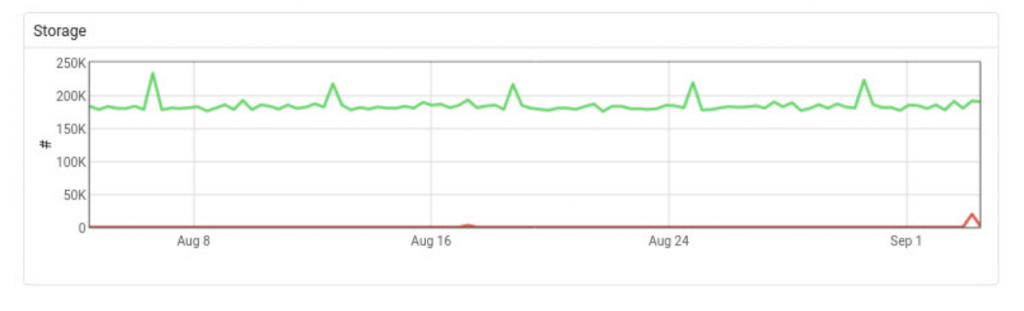
Comment on storage data: This data is very useful to determine the iops value of the PEM server, especially when the number of the database servers increase. 1 DB server and 1 PEM server does not hurt the storage, but especially the write performance will be important while collecting the data when there are a lot of database servers. This also may end up with optimizing PEM database as well. Please refer to our tuning guides for tuning RHEL family for PostgreSQL or tuning Debian/Ubuntu for PostgreSQL guides for details.
Memory usage data
Memory: 7 days
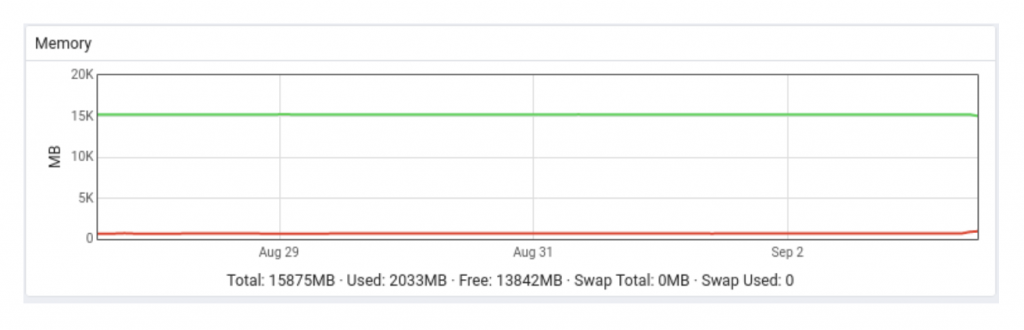
Memory: 30 days
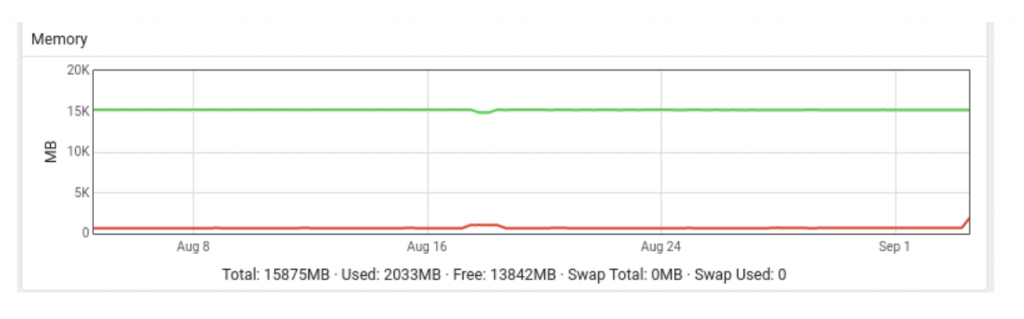
Comment on memory usage: Unsurprisingly memory usage is low on PEM server -- but please note that as the number of agents increase, database connections will also increase, so memory usage will be higher.
Conclusion
In order to control the disk growth of PEM, the main tip is decreasing the retention periods of the probes. Also, increasing execution periods of the probes may help -- however please note that decreasing execution time may also end up with losing some important data, so use it as a second option.
Database size peaked to 1.4GB after 30 days, which is the retention period we defined above. After garbage collection kicked in, DB size decreased a little, but with the help of autovacuum the db size did not increase even after inserting new data.
The disk I/O will be critical as the number of database servers increases. Each agent will collect the data, and that data will be written to the Postgres. This will affect both memory usage, WAL amount, CPU usage and database size. Also, reading the data will be crucial, so the resources of the PEM server will need to be increased after adding several monitored database servers.
Relevant Blogs
Release Radar: New Postgres Extension Support Announced in Fully Managed BigAnimal Postgres-as-a-Service
EDB is one of the major contributors to Postgres, and we are dedicated to enabling our customers maximize their Postgres database environments by leveraging both EDB commercial and open source...
EDB BigAnimal: The Complete Postgres-as-a-Service Experience
There’s a lot to consider when making decisions around hosting and managing your PostgreSQL instances. The life of a database administrator is complex, and day-to-day operations are always subject to...
Unlock Possibilities with Free Postgres Training from EDB
Postgres is the database of the future. In recent years it’s skyrocketed in popularity across industries and established itself as the go-to database for innovators. It’s considered the most loved...More Blogs

Solving Your DBA Talent Gap: Upskill vs. Outsource
For businesses looking to leverage the full potential of Postgres database, there are few roles as important as database administrators (DBAs). DBAs provide vital management and monitoring for your organization’s...